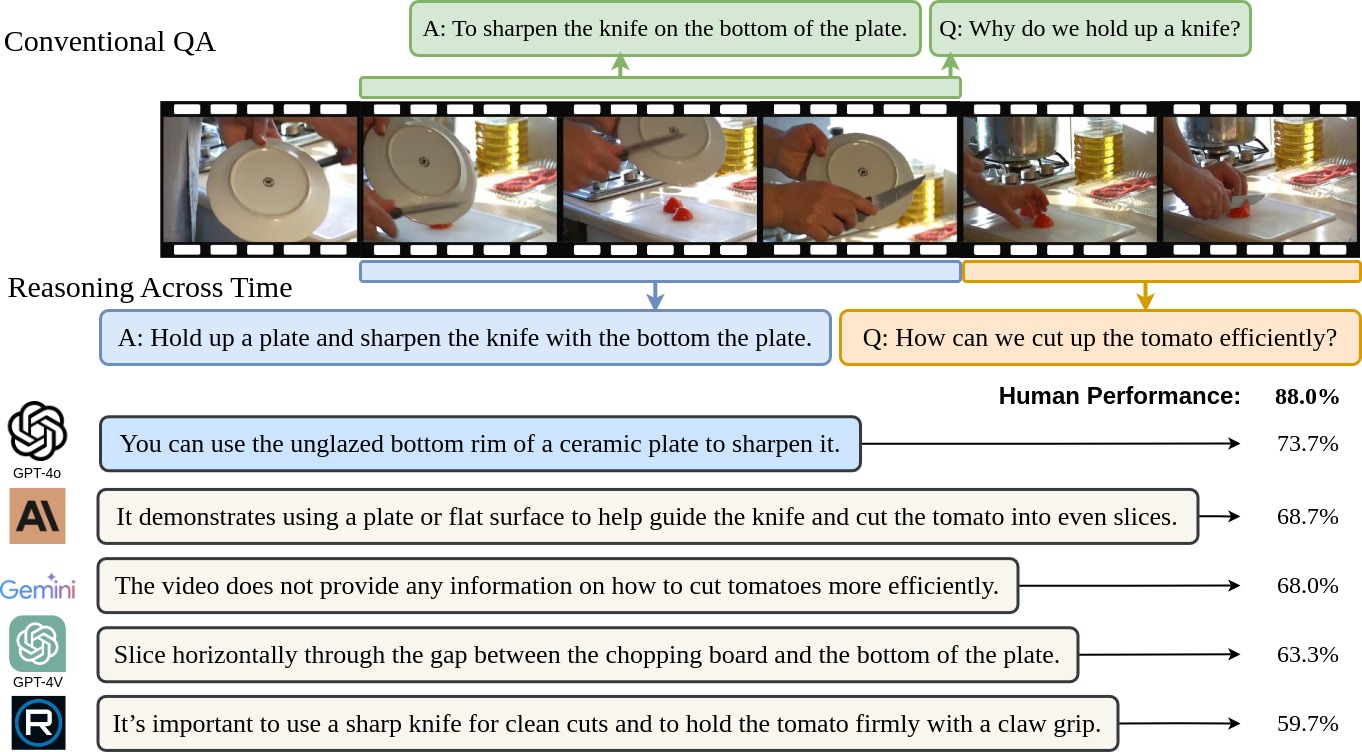
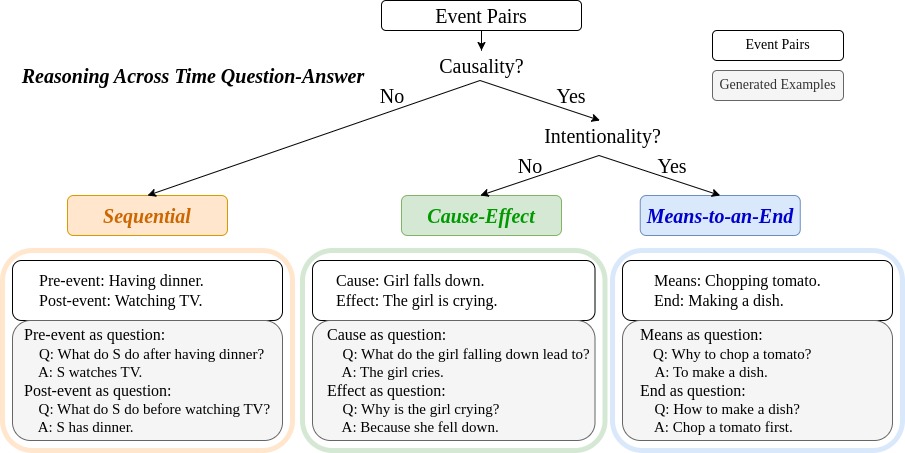
Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have nearly matched human performance in various language and vision-language tasks. Notably, frontier MLLMs trained on web-scale proprietary datasets show impressive video understanding such as GPT-4o, Gemini-Pro-1.5 and Claude-Core. However, unlike LLMs which excel in text reasoning over long sequences, the cause-effect reasoning in MLLMs, especially in understanding long video events, remains under-explored. In an initial study, we identified a common shortcoming in the most advanced MLLMs -- they struggle with video question answering when the question and answer correspond to different time segments. As shown in Figure 1, the question”How can we cut up the tomato efficiently?'' and the answer “Hold up a plate and sharpen the knife on the plate.'' each refers to separate segments. Surprisingly, a simple question like this can challenge leading MLLMs. Therefore, there is a pressing need for a benchmark to quantitatively assess video temporal reasoning. To address this, we introduce ReXTime, a benchmark to evaluate Reasoning-Across-Time capabilities for video events.
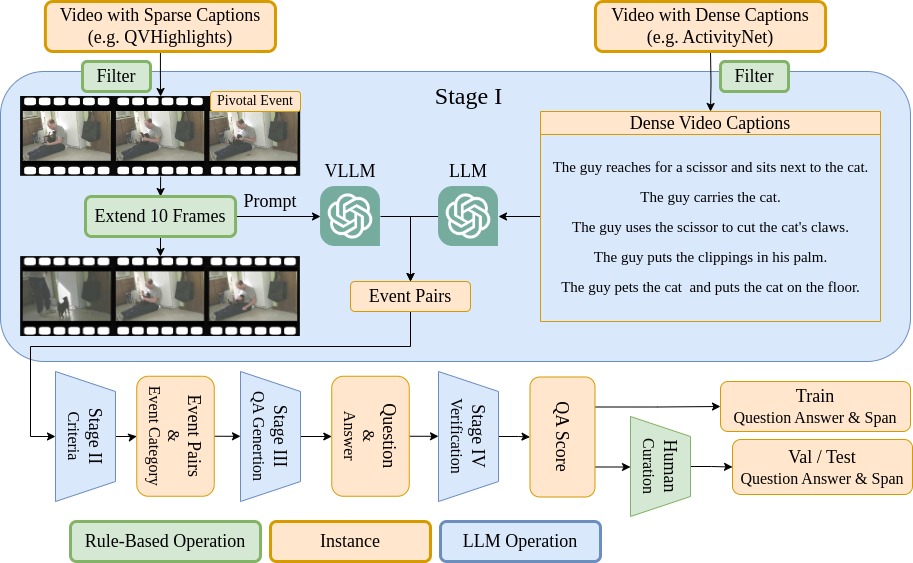
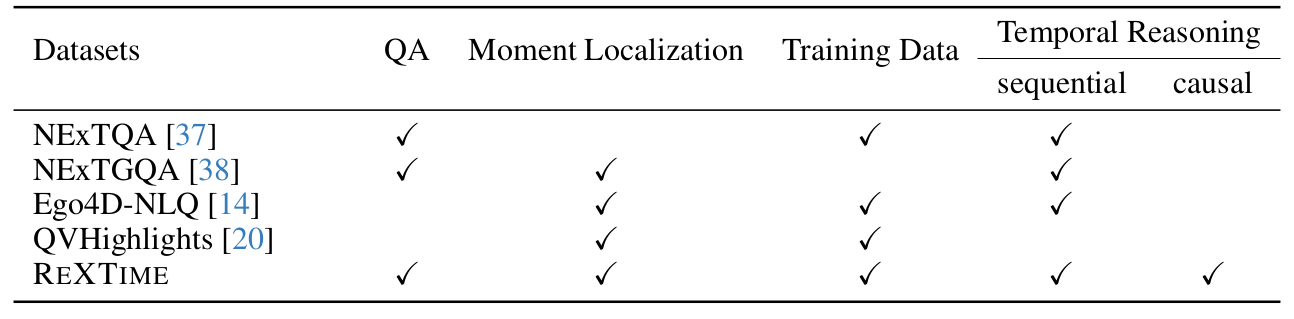
To develop ReXTime, we propose an LLM-assisted data generation pipeline that minimizes human effort and cuts costs from $300 to $135 per 1,000 QA pairs. The benchmark includes 921 validation and 2143 test samples, each rigorously curated by human annotators. Empirical evidence indicates that even proprietary frontier MLLMs are inadequate for temporal reasoning. For instance, humans can achieve 88.0% accuracy on VQA tasks, whereas the top-performing MLLM, OpenAI's GPT-4o, only reaches 73.7% as shown in Figure 1. A new benchmark such as ReXTime has the potential to significantly propel advancements in this field -- it effectively differentiates between model capabilities, and the state-of-the-art model has not yet saturated human-level accuracy. The additional 9695 unverified samples provide a training dataset that has significantly boosted an academic MLLM's temporal reasoning skills, lowering the entry bar for future research. Furthermore, we confirmed that \ours primarily contains reasoning across time questions, with the lowest question-answer overlap in time (QA-mIoU) compared to other video QA benchmarks.